👓 Wearing glasses doing math improves division
Late to the Party 🎉 is about insights into real-world AI without the hype.

Hello internet,
what a week, it looks like tech is further imploding. Let’s look at some machine learning instead!
The Latest Fashion
- Stability AI is being sued by artists over Stable Diffusion publicly.
- This book about Understanding Deep Learning goes deep.
- This “course” about learning prompt engineering was really insightful.
Got this from a friend? Subscribe here!
My Current Obsession
I was in Luxembourg this week to record videos for the second tier of our MOOC about machine learning for weather and climate prediction. I will present on deep learning, which was quite a challenge to fit into about 30 minutes of video. I have taken a bit of a different approach to what I usually see in courses with a primary focus on convolutional neural networks and commonly used architectures in real-world machine learning. Hope it’ll work out!
Thing I Like
I got a little whiteboard for my desk to keep notes and little distractions. Wish I had known this exists earlier!
Job Corner
There are a few open positions from the community:
Manuel reach out that EY Spain is hiring both Junior and Senior Data Scientists for their centre of excellence! You can learn more and reach out on Linkedin.
And Open AI is hiring as well, but you’ll have to go the conventional application route.
Machine Learning Insights
Last week I asked, “How can you deal with high-variance datasets in machine learning?”, and here’s the gist of it:
When it comes to machine learning, dealing with high-variance datasets is quite a challenge. “High-variance”, specifically, is when there is a lot of difference or variation between the data points in a dataset. That makes it hard for machine learning models to predict outcomes accurately.
There are a few things we can do to deal with a high-variance dataset in machine learning.
One of the most effective ways is to gather more data. The more data we have, the more representative it will be of the overall population. This will often help to reduce the amount of variation in the dataset.
Another way to deal with high-variance datasets is to use regularization techniques. These are methods that help to prevent the model from overfitting, which is when it becomes too focused on the specific data points in the dataset and doesn’t generalize well to new data. Here you can use classic regularization techniques like L1 and L2 but also dropout in neural networks.
Finally, you can also use feature selection methods to help deal with high-variance datasets. I shared some resources for Leave-One-Feature-Out methods a while back. These are techniques that help you to identify which features of the data are the most important for making predictions. By only using the most important features, we might be able to reduce the amount of variation in the dataset and improve the performance of the model.
Let me know if I missed your favourite!
Data Stories
2022 has seen a lot of wildfires in Europe.
I love a fancy visualization, and the source I posted below has a lot of them. However, the one below is simple and tells a harrowing story.
It is easy to grasp and says one thing: The fires started earlier and with a much higher impact.
Really shows how a simple graph sometimes works incredibly well.
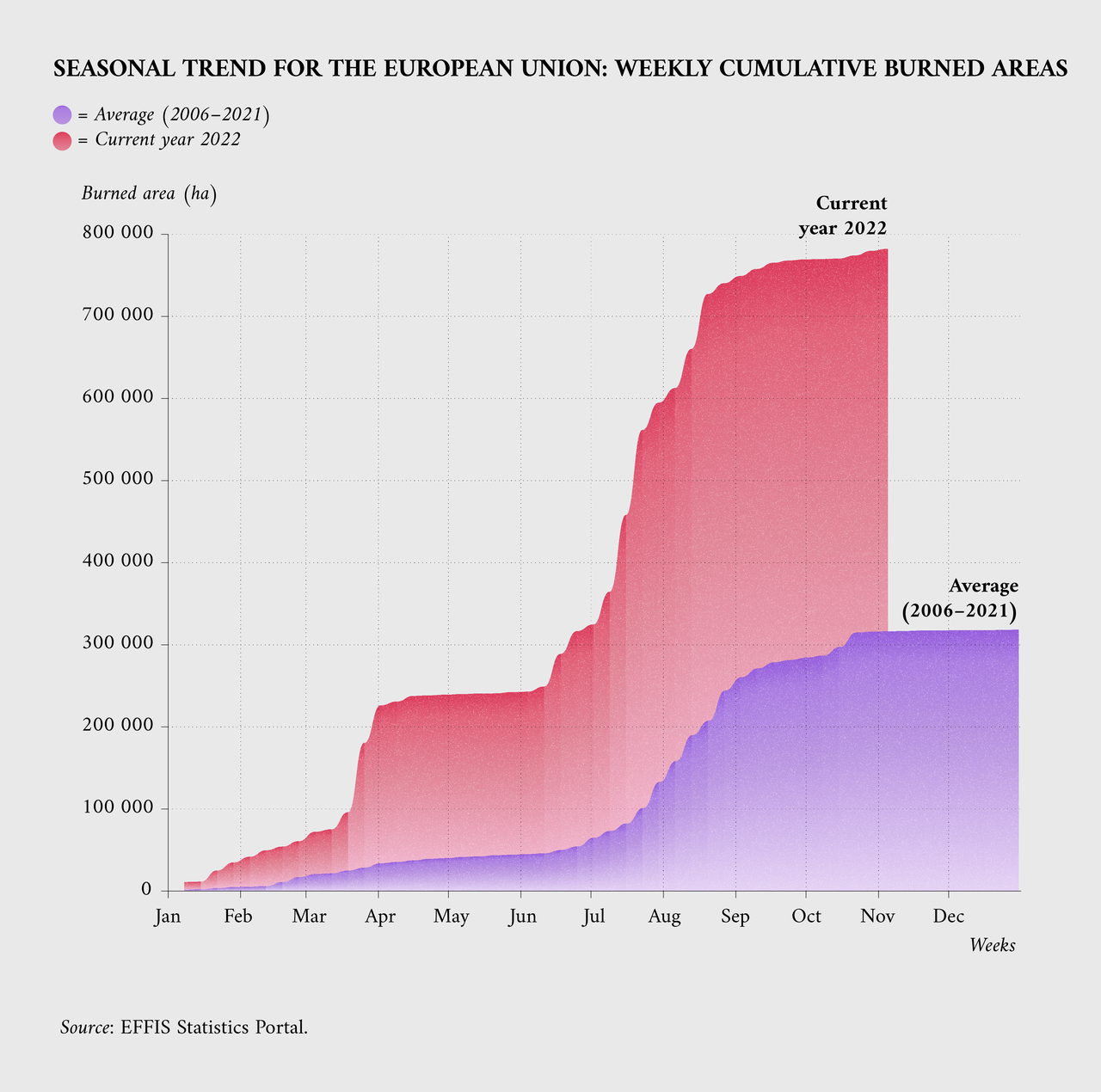
Source: European Commission
Question of the Week
- Could you describe your normal data science workflow?
Post them on Twitter and Tag me. I’d love to see what you come up with. Then I can include them in the next issue!
Tidbits from the Web
- This web presentation about 4000 weeks is beautiful and uncomfortable.
- You can add chatGPT to your Google (or even SearX) searches!
- This chatGPT answer wins the internet.
Add a comment: