🍝 The poor Italian chef was unfortunately Penne-less
Late to the Party 🎉 is about insights into real-world AI without the hype.

Hello internet,
Apologies for the miss, I’ll explain below. Let’s talk about machine learning first!
The Latest Fashion
- Visual labeling of data right in your Jupyter notebook
- This Python linter written in Rust is incredibly fast
- They warned Google about sentient AI hype… last year already! History repeats itself
Got this from a friend? Subscribe here!
My Current Obsession
Apologies for the missed issue last week. I was having a bit of a mental breakdown, unfortunately, and had to prioritize my safety. But we’re back on track and have some fun things planned!
I gave a lot of talks over the last weeks. You already heard about my talk at Brown University, then I spoke to a data science community of practice, and finally, I talked about community building at the Software Sustainability Institute.
The Latent Space is slowly coming along, and I started posting my old links from this newsletter and having regular accountability check-ins. It’s slowcial media and I’m liking the laid back nature of it.
Thing I Like
I busted out my slow cooker again and made some incredibly tasty chili. Glad I can still make that staple of a stew after such long time. It’s one of these with a digital clock, so it turns off after a set time.
Hot off the Press
I was pre-occupied preparing talks, so I couldn't really get into writing as much, but I already have a few good ideas lined up.
In Case You Missed It
It looks like more people are brushing up on their resumes and finding my advice on projects NOT to include!
Machine Learning Insights
Last week I asked, What is the difference between parametric and non-parametric models?, and here’s the gist of it:
Parametric models make assumptions about the underlying distribution of the data, such as the data being normally distributed. These models use a fixed number of parameters to represent the data. The parameters are estimated using statistical techniques like maximum likelihood estimation. Examples of parametric models include neural networks or Naive Bayes.
Non-parametric models, conversely, do not make any assumptions about the underlying distribution of the data. These models are flexible and can represent complex relationships between the input and output variables without specifying a particular functional form. Non-parametric models can handle a wide range of data types and are particularly useful when the underlying distribution of the data is unknown or cannot be easily modelled. Examples of non-parametric models include random forests and support vector machines.
Let's illustrate the difference between these two types of models with an example from meteorological data. Consider a dataset of daily rainfall measurements for a particular location over one year. We could predict the likelihood of rain on a specific day based on historical rainfall measurements and other meteorological variables like temperature and humidity.
A parametric model, like a neural network, would assume that the data follows a particular distribution. The model would estimate the parameters of the distribution based on the data and use these parameters to make predictions about the likelihood of rain on a given day.
A non-parametric model, like a decision tree or random forest, would not make these assumptions about the underlying distribution of the data. An SVM, for example, would be flexible and could capture complex relationships between the input variables and the output variable without assuming a particular functional form. However, we often have to use a kernel to make the data separable in lower dimensional spaces to avoid the SVM from taking years to find a little hyperplane in your data.
In summary, parametric models make assumptions about the underlying distribution of the data and use a fixed number of parameters to represent the data. In contrast, non-parametric models do not make any assumptions about the data distribution. The choice between parametric and non-parametric models depends on the nature of the data and the specific problem being addressed.
Data Stories
In my circles, Buzzfeed always was in a credibility crisis.
They were known for listicles with a GIF for each point instead of content and viral quizzes of which loaf of bread you are. Their investigative journalism branch was super interesting to me, but when I shared it around, folks would usually mock the source (and maybe also me a bit, but I can deal with that.)
Buzzfeed News, the news branch of the former digital media darling, just closed its doors and left a lot of people scrambling for new jobs.
Chartr tells an interesting visual story with more background in the link below!
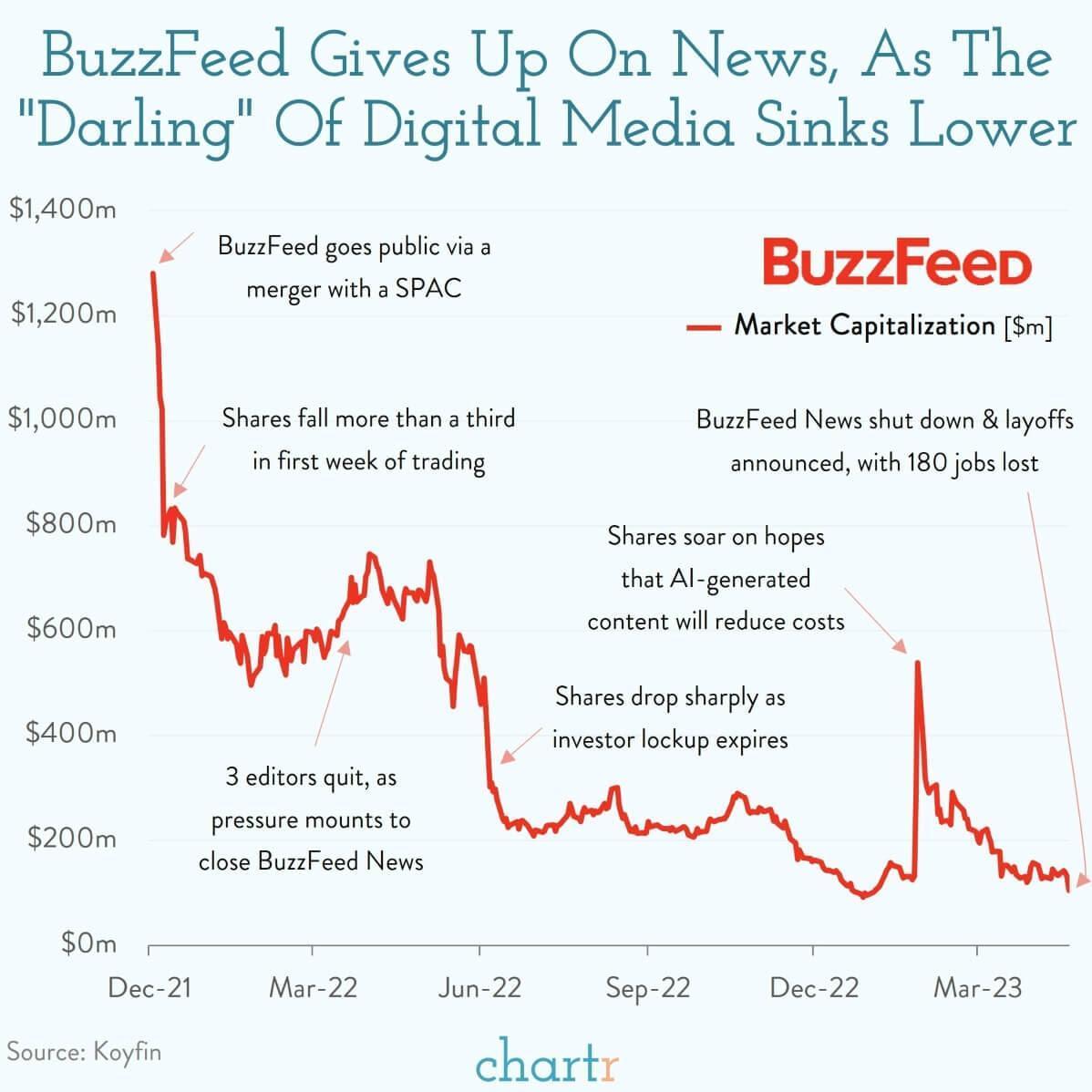
Source: Chartr
Question of the Week
- Can you name good example problems to apply machine learning to?
Post them on Mastodon and Tag me. I'd love to see what you come up with. Then I can include them in the next issue!
Tidbits from the Web
- I learned about the mathematician Cleo in this Tiktok
- Quiz: Is it AI or is it real?
- It’s time to let coal die.
Add a comment: