👻 I do my hair with scare spray on Halloween
Late to the Party 🎉 is about insights into real-world AI without the hype.

Hello internet,
What a beautiful week. Let’s look at some spooooky machine learning!
The Latest Fashion
- Tricks and Tools to write efficient Python in Data Science
- You can now get a Rubber Ducky AI for VSCode
- Learn Neural Networks: Zero to Hero free on Youtube by the Karpathy
Got this from a friend? Subscribe here!
My Current Obsession
I splurged a bit on getting a cleaner for my flat, and it was so worth it. It gave me the necessary momentum to tidy up some long-standing issues in my flat. That was incredibly helpful! Also good to support some local freelancers, as always.
We had a lovely board game night at work as well. I forgot how much I missed playing board ames. Great fun!
Other than that I’m getting ready for Halloween. I somehow really enjoy the spooky season! 👻
Thing I Like
I bought some pumpkin carving tools to carve pumpkins with a friend, and I have to honestly say it was worthwhile. They came out great, and it was good fun working with the specialised tools!
Hot off the Press
I posted my story of messing with missing data the first time.
In Case You Missed It
My article on the challenges in machine learning in weather I learned about in the last 2 years is somehow still really popular. Should I share more of these insights?
On Socials
I wrote a story of how I lost $57 due to missing data during a hackathon.
I spent some time writing on Linkedin to unlock the “Linkedin Machine Learning Top Voice” badge. My writing on how domain expertise helps in feature engineering, my comment on the difficulty of creating projects in deep learning curricula, and my training strategy for noisy data in CNNs, were quite popular!
Mastodon really liked learning about building GPT in 60 lines of Numpy.
Python Deadlines
The FlaskCon deadline is coming up!
Machine Learning Insights
Last week I asked, What is the most over-hyped method in machine learning in your opinion?, and here’s the gist of it:
While machine learning has brought about many powerful techniques, there are certain methods that have been hyped to an extent that may not always match their real-world effectiveness. One such method, in my opinion, is SMOTE (Synthetic Minority Over-sampling Technique) for data balancing.
SMOTE for Data Balancing: SMOTE is a technique used to address class imbalance in machine learning datasets. Class imbalance occurs when one class of data (e.g., a rare disease or an extreme weather event) is significantly underrepresented compared to another class. SMOTE works by creating synthetic examples of the minority class to balance the dataset.
Why It's Hyped: SMOTE gained popularity because it seems like a straightforward solution to a common problem. It's easy to implement, and it gives the impression of solving class imbalance issues. As a result, it has been widely recommended in various papers and blog posts.
The Reality: Class imbalance can be a problem, usually when the class imbalance supersedes a 1 to 10 ratio to the majority class. But I have yet to see SMOTE work on real-world data. Here are some of the realities
- Sensitive to Noise: SMOTE can generate synthetic samples that are noisy or irrelevant, which may negatively impact model performance.
- Modelling Assumptions: The SMOTE algorithm makes certain assumptions of linearity to interpolate new samples in the data space. In highly complex or non-linear systems, this assumption already breaks down.
- May Not Address Underlying Issues: Balancing classes is essential, but it doesn't necessarily address the root causes of class imbalance. For some problems, collecting more data for the minority class or redefining the problem may be more effective.
Meteorological Data Example: Imagine you're working on a weather prediction model, and you want to predict rare and extreme weather events like hurricanes. These events are infrequent compared to typical weather patterns. If you use SMOTE to balance your dataset, it may generate synthetic hurricane data points. However, these synthetic hurricanes might not accurately represent the complex dynamics of real hurricanes. As a result, your model's ability to predict actual hurricanes may be compromised.
My Personal Conclusion
Personally, I have yet to see an application where SMOTE holds up to its promise, which can’t be addressed by simply over- or under-sampling or collecting more data. In the end, we have to calibrate the classifier anyway to accommodate for the realities of rare events.
Data Stories
I was browsing Reddit when I found this beauty!
Visual Geomatics, who sells these maps, posted the mid-Atlantic ridge, a fascinating relief in our world.
The Mid-Atlantic Ridge is an underwater mountain range that stretches down the centre of the Atlantic Ocean and covers over 16,000 km of ground.
It is fascinating, honestly, because it forms from the North American and Eurasian tectonic plates moving apart.
Because this ridge continuously produces new rock from the centre of the Earth, we can learn some amazing things!
A big one, was when they measured the magnetic alignment of the rock around the ridge.
The researchers first thought they had made a huge mistake in their measurement!
There are stripes parallel to the ridge!
Turns out, that due to the cooling of the rock, it “froze” the Earth’s magnetic field in a sort of time capsule.
Proof that periodically (on geologic timescales), the Earth’s magnetic field flipped!
Additionally, it’s just really pretty, which is why I love this map!
The image was created by using a technique called hill-shading that creates realistic looking 3D-effects on 2D images.
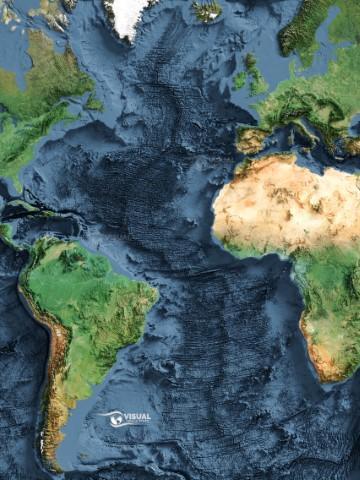
You can buy it here and check out many more maps!
Question of the Week
- How do you ensure machine learning models don’t over-predict rare events?
Post them on Mastodon and Tag me. I'd love to see what you come up with. Then I can include them in the next issue!
Tidbits from the Web
- Just a pumpkin on vacation doing pumpkin things.
- We played the game Ubongo during game night, and it was really fun!
- The laws of physics still work.
Add a comment: