🚗 Don't let seismologists drive. They're often at fault
Late to the Party 🎉 is about insights into real-world AI without the hype.

Hello internet,
the trial month of 2023 is over. How did it go? I’m neither entirely disappointed nor jumping with joy. But let’s jump right into some machine learning instead!
The Latest Fashion
- There’s a new Coursera by Deepmind on the mathematics of machine learning
- Looks like the self-driving Tesla video was fudged at request of Elon Musk, reported by Bloomberg
- Huggingface debuted their own machine learning competition platform with “AI or Not”
Got this from a friend? Subscribe here!
My Current Obsession
It’s been a quiet week. Unfortunately, I got very sick, so I watched Critical Role and barely left my couch.
After a few of you followed up with me about that, I have been thinking more about building out that community. I think it has a place in the current breaking apart of Twitter, weirdness on Instagram, and yelling matches on Linkedin. Mix in the commodification of cheap content with chatGPT and AI art, and I genuinely think it may be worth building smaller communities of practice. Additionally, the Slack that accompanied NormConf was just really lovely and is now shut down. I’m thinking more about this since I want it to be excellent but also sustainable. I tend to do too many things, and I don’t want this to form resentment within me over the amount of work I prescribe myself. Anyways you’ll be first to know about new developments.
Thing I Like
I bought myself a visual timer. They’re quite highly recommended in ADHD circles, and so far, it’s been great as a cue for breaks and to get some quick tasks done!
Hot off the Press
I shared a text analysis tool in Python with the web, and it’s been quite popular. Pushed me over 16,000 followers on Linkedin!
In Case You Missed It
Don’t include these data science projects on your resume!
Machine Learning Insights
Last week I asked, “Could you describe your normal data science workflow?”, and here’s the gist of it:
A typical data science workflow typically involves several steps:
- Defining the problem: This is the first step in any data science project, where I work with my team or client to understand the problem that needs to be solved. This includes identifying the goals of the project, the available data, and any constraints that need to be considered.
- Data exploration and cleaning: Once I clearly understand the problem, I start exploring the data to understand its structure and identify any issues that need to be cleaned or preprocessed. This step can take a significant amount of time, as data is often messy and requires a lot of cleaning and preprocessing before it can be used for analysis.
- Feature engineering: After the data is cleaned, I create new features or variables used in the analysis. This step is crucial as it can help improve the performance of the models.
- Model selection and evaluation: Next, I select an appropriate model to solve the problem, then train and evaluate the model using various metrics. This step may involve trying multiple models and comparing their performance.
- Deployment and monitoring: Finally, if the model performs well, I deploy it in the production environment and monitor its performance over time to ensure it continues to work well.
- Iteration: Based on the monitoring and feedback, I may need to iterate back to the previous steps to improve the model performance.
It’s worth noting that this is a general workflow and may vary depending on the specific project or problem.
I walk through these steps in my Skillshare course.
Data Stories
This video of earthquake activity in Iceland in 2022 is mesmerising.
The data consists of 35,000 earthquakes validated by the Icelandic Met Office and made with QGIS for every day. You can explore the data itself here: skjalftalisa. vedur.is
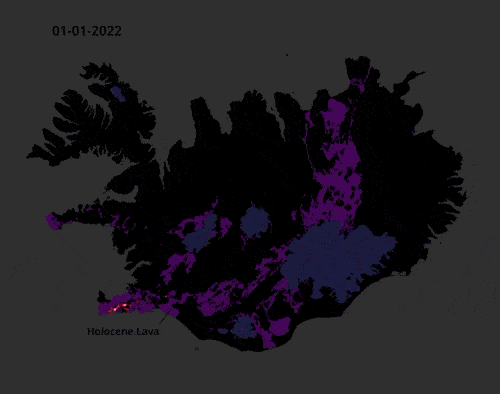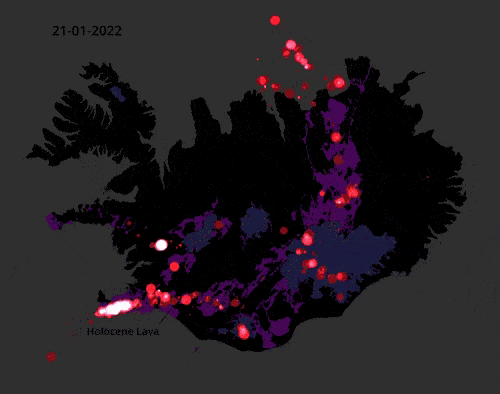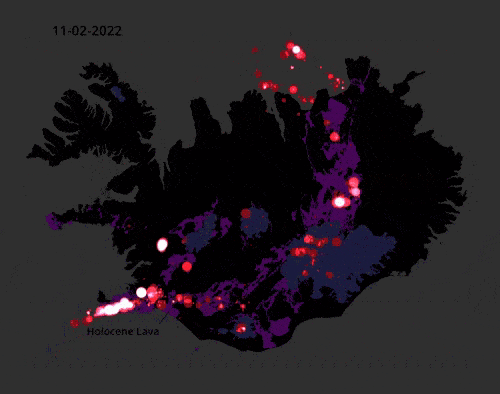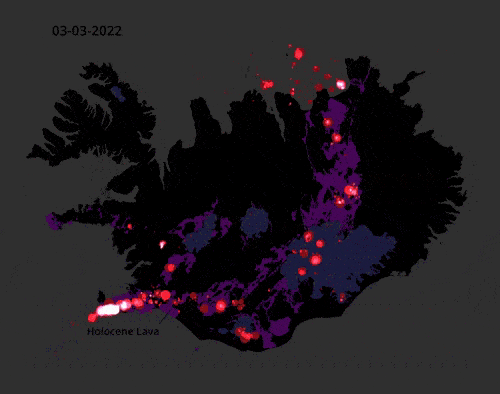
Source: Ragnar Heiðar Þrastarson
Question of the Week
- Name a few examples of kernels in an SVM or Gaussian Process.
Post them on Twitter and Tag me. I’d love to see what you come up with. Then I can include them in the next issue!
Tidbits from the Web
- I love the “Fool Us!” series, and this card trick is absolutely incredible even if you don’t like magic.
- When you played through chatGPT try out the best version: CatGPT
- Turns out only 4.9% of Danish cyclists commit road rule violations. Motorists? 66% despite contrary perception.
Add a comment: