🛸 Does Kirk order coffee asking: Bean me up, Scotty?
Late to the Party 🎉 is about insights into real-world AI without the hype.

Hello internet,
Another week passed already?! Time flies when you’re having fun… and machine learning!
By the way, there's now 1,100 of you! Welcome everyone!
The Latest Fashion
- OpenAI finally scuttles their AI text detector for low accuracy
- This blog article poses that transformers are bad at math because attention is off-by-one
- On that note, I had these formal algorithms for transformers in my collection for a while
Got this from a friend? Subscribe here!
My Current Obsession
I finished the certification as Mental Health First Aider! Pretty proud of that one.
I’m checking out the Impactful Social Writing course. So far, it’s got a bit of overlap with other courses I have taken so far, but I’m less than halfway through. The presenters seem very knowledgeable and personable, so I look forward to the rest. Hope I can get my humour across in writing a bit better from time to time. We’ll see!
I have also started moving my data away from Google. Their announcement that your Google Docs and Gmail will be used to train their LLMs is unacceptable to me. I am currently trying out Proton Mail, which seems to be doing a lot of things right. That whole migration with all my filters, calendars, and labels has taken multiple days since the system migrated over 180,000 emails for me. So far, I really like it, though!
And my new chatGPT course already has 150 students in less than two weeks, which is absolutely unbelievable!
Thing I Like
I’ve been reading on my Kindle Paperwhite a bunch lately, especially after making my balcony all nice and cosy. That has been a delight!
Hot off the Press
I published this short about data science boot camps.
On socials, I re-shared Parsr for document parsing, which was popular on Linkedin (obviously). Mastodon enjoyed Chip Huyen’s resource on the power of streaming data.
In Case You Missed It
Back in the day, I open-sourced my entire PhD thesis, so I figured I’d re-post it to Linkedin, and it went fairly viral! That makes me particularly proud!
Machine Learning Insights
Last week I asked, What is your top priority in making a machine learning experiment reproducible?, and here’s the gist of it:
My top priority in making a machine learning experiment reproducible is ensuring that all aspects of the experiment are well-documented and that the code, data, and configurations are organised and versioned.
Reproducibility is the ability to recreate the exact same experimental results using the same code and data. It is crucial in machine learning research and applications as it allows others to validate and build upon the work, fostering collaboration and trust in the field.
To achieve reproducibility in a machine learning experiment, I focus on the following key aspects:
- Version Control: Using a version control system like Git is essential to keep track of changes in the code, data, and configurations. By committing the code and data to a repository, we can quickly revisit past states of the project, ensuring that others can reproduce the experiment we conducted.
- Code Organization: I ensure the codebase is well-structured and modular. This means breaking down the code into functions and modules that are easy to understand and reuse. Properly organised code reduces confusion and makes navigating and replicating the experiment simpler for others.
- Data Management: Managing data carefully is critical for reproducibility. I keep a separate directory for data, clearly documenting the sources and preprocessing steps. If the data is not publicly available, I ensure that there is a transparent process for obtaining it or providing a suitable alternative for replication.
- Configurations and Hyperparameters: I use a configuration management system like Hydra (as mentioned in a previous response) to keep track of hyperparameters and experiment settings. This allows easy experimentation with different configurations and ensures that others can reproduce the experiment with specific settings.
- Seed Control: Randomness is common in machine learning, such as random weight initialisation or data shuffling. I set seeds for the random processes to ensure the reproducibility of the experiment. This way, anyone running the experiment with the same seed will get the same results.
- Documentation: I maintain clear and comprehensive documentation of the experiment. This includes explaining the purpose of the experiment, detailing the methodology, and providing explanations for significant decisions made during the process. Proper documentation aids others in understanding the experiment and reproducing it accurately.
By focusing on these aspects, I prioritise making the machine learning experiment reproducible, contributing to the advancement and trustworthiness of the field.
Solomon Schuler started a pleasant conversation about the necessity of open-source libraries on Mastodon, and here’s an excellent, succinct overview of the availability of data and the source code for the training. And, of course, we have my overview on ml.recipes with reusable code and lots of explanations about model sharing.
Data Stories
Data Science interviews usually have a good portion of statistics in them.
But which concepts are the most important?
Emma Ding, who consults about and creates content around data science interviews, has analysed the data:
Those p-values don’t get old, and you’ll need your standard tests, correlations, and a bit about different errors. Would be great if you could explain a linear regression as well!
Probably worth a follow!
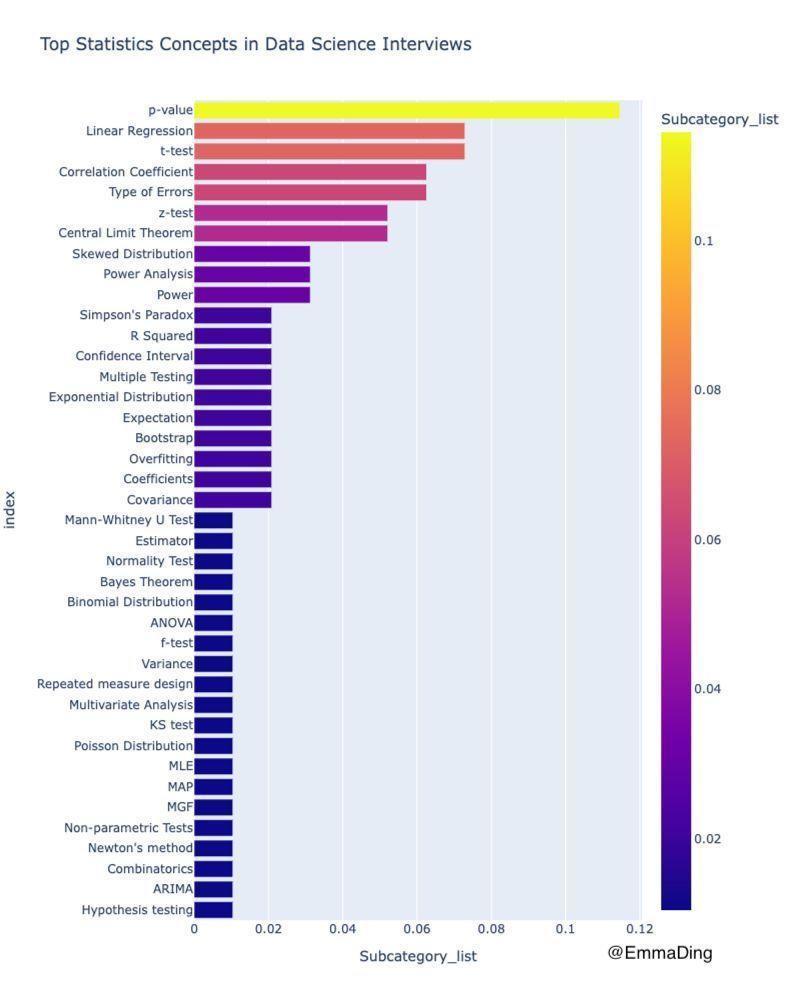
Source: Emma Ding
Question of the Week
- What’s the difference between ML engineers and ML scientists?
Post them on Mastodon and Tag me. I’d love to see what you come up with. Then I can include them in the next issue!
Tidbits from the Web
- Is CodeBullet out of touch?
- This satire of finance bro podcasts is way too real
- I found this app you can build routines that has been helping my neurodivergent brain lately!
Add a comment: